Beam Test Pipeline Application
and Processing Chain
Introduction
Generally stated, a pipeline consists of tasks and processes created and chained together to implement a multitasking environment on a server. Major components normally include such things as:
- Scheduler/Rules engine
- Task file (e.g., XML) import/export
- Task Database
- Data Catalog database
- Processing history database
- Web interface
- Batch submission interface
- Conditions interface (disk space/usage monitoring, etc.)
GLAST Pipeline. The current GLAST Pipeline (a.k.a. Pipeline I) is a system for scheduling and tracking the execution of data processing jobs on SLAC's CPU farm.
Terms used in Pipeline processing:
- Pipeline Application - A pipeline task designed to define meet a specific need and submitted to the pipeline scheduler in the form of a task file.
- Job - A single unit of batch submission, usually a script submitted to the batch system. Current pipeline processing consists of one batch submission step.
- Run - A number used to label a collection of event data, usually contained in a single file (or multiple files if the amount of data exceeds the maximum file size) for a given data type, e.g., Merit tuples, MC, Digi and Recon ROOT trees.
- Task - Data generated from the same code and configuration. Typically, a task contains a large number of runs. Task names are stored in the Pipeline Database and can be used to generate a list of corresponding data files.
Two pipeline applications have been created in support of the Beam Test:
- Monte Carlo Pipeline (for Beam Test)
- Beam Test Pipeline (to process the BT LAT Data)
Beam Test Pipeline
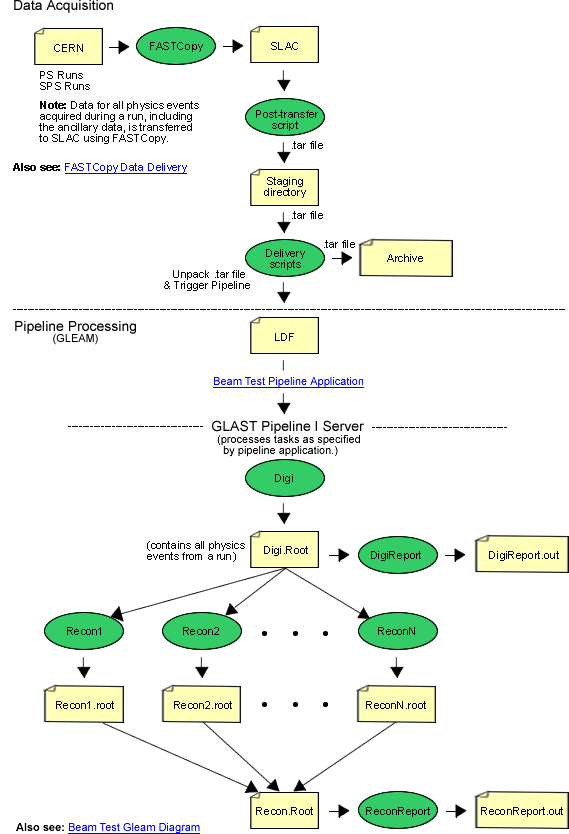
The Beam Test Pipeline application consists of a configuration of data processing jobs submitted to the Pipeline I scheduler. (See Beam Test Pipeline flow chart.)
Once the first task (updateELogDB) is started and exported from Pisa or CERN, it's all automatic unless something fails.
All online data produced by LATTE (currently stored in directories associated with runs numbers) are automatically retrieved and FASTCopied to the SLAC farm. After that, an ORACLE database is populated which provides queries to the data. The pipeline also creates reports, and launches data processing/reconstruction code to produce data files and high level analysis ntuples.
The normal sequence can be summarized as follows:
- From LATTE, format to digi.
- Generate digiReport.
- Run recon on the digi file.
- Generate reconReport.
- Generate BT tuple.
- At all stages populate the ElogDatabase when appropriate.
Notes:
- The sequence of steps within a beam pipeline task is set by an XML file uploaded via the GINO front end to create the task. This file also sets up input and output files, what code to run, which batch queues to run it on, etc. The XML files are generated by perl scripts in the task directories under $beamtestPlRoot.
- Tasks launch other tasks using the $beamtestPlRoot/lib/TaskLaunch.pl script. By convention, each task is launched in a separate task process (TP). The TP, script, and the wrapper it uses have names beginning with "Launch".
- There is no file, script, datastructure, or anything that codifies the global structure; tasks launch other tasks without GINO understanding it.
Beam Test Processing Chain
The Beam Test Pipeline Application is a part of the Beam Test Processing Chain shown below and consists of a configuration of data processing jobs submitted to the Pipeline I scheduler.
Note that the Beam Test Pipeline submits jobs to the Pipeline I scheduler which then schedules the jobs on the SLAC CPU farm. Once the first task (updateELogDB) is started and exported from Pisa or CERN, it's all automatic unless something fails.
Beam Test Data Processing Chain
Reading Ancillary Data
Ancillary data fields are read from rcReport, but they are not put in a file. However, they can be read by a database query (e.g., ./lib/queryElogReportTable.pl 700000597 beam_momentum), but only on SLAC machines.
Note: Runs prior to 700000529 did not have any of the new fields entered.
Beam Test Data Monitoring
To see if a run is processed:
- Go to: Beam Test Data Monitoring.
- Enter the version of the current set of beamtest tasks (e.g. v1r030603p4) and click on the Filter button. If none of them are "Waiting", "Running", or "Finalizing", they are done.
Also see: GLAST Pipeline Front End (PFE) tutorial.
Test a New Version of a Script
To test a new version of a script:
- Instead of installing the scripts on ~glast/pdb_config/dpf_config_prod.csh, install the new script on the test pipeline server:
source ~glast/pdb_config/dpf_config_test.csh
- Reprocess an old run by running:
$beamtestPlRoot/online/BeamTestLaunch.pl $runId
Tip: Everything should be set up in: $beamtestPlRoot/setup/svacPlSetup.cshrc
Note: Instructions for installing a new version of the scripts can be found in:
$beamtestPlRoot/doc/install.txt
Troubleshooting
Tracking Down a Problem
- First go to the Pipeline Front End (PFE) and determine where it failed:
- Then look at the log file to determine which task process that failed.
(Refer to the GLAST Pipeline Front End (PFE) tutorial.)
Tip: A failure is often due to a transient problem and can be fixed by:
$PDB_HOME/rollBackFailedRun.pl $task $run
Note: If the failure is due to a bug in the pipeline code, and you choose to check the code out and modify it:
- First, test the bugfix on the test pipeline server.
- Then ask the Change Control Board (CCB) for permission before installing the bugfix in production code.
Halt Pipeline Processing
It is safe to turn off injection by touching the "halted" file while runs are being processed. Runs that were already injected will continue to be processed, but new runs will not be injected until the file is removed.
Caution! Do not change the "current" link while runs are being processed.
Cleanup Pipelines (after failed recon run)
SVAC and Beamtest Pipelines:
To cleanup the SVAC and Beamtest pipelines after a failed recon "chunk" run on a noric machine, run either of the following scripts:
$svacPlRoot/lib/cleanupRecon.csh
or
$beamtestPlRoot/lib/cleanupRecon.csh
Note: Either script will cleanup both the SVAC and Beamtest pipelines. However, while they will try, they cannot cleanup the test pipeline due to permission settings.
Test Pipeline:
To cleanup the test pipeline, run it ast glast.dpt (using the same password as for glast/glastdpf).
Reprocessing a Run
To reprocess a run:
- Delete the old links :
$beamtestPlRoot/lib/deleteLinks.csh $run
- Then enter:
$beamtestPlRoot/online/BeamTestLaunch.pl $run
Note: If reprocessing runs stored on an older disk, create a script to reprocess runs stored on the old disk by copying BeamTestLaunch.pl, then create links to the old data before launching createRun.pl. BeamTestLaunch.pl only works for runs where the LDF file is on the current raw data disk.
For example, at the time this document was written, the current disk was u37; however, the ldf files taken to date were written to u30, and a script ($beamtestPlRoot/online/u30Launch.pl) was created to reprocess those runs.
Tips:
- Code can be checked out from:
/afs/slac.stanford.edu/g/glast/ground/PipelineConfig/BeamTest-tasks/beamtestPipeline/versionNumber
(e.g., v1r030603p4)
- To view install.txt, go to the CVS Repository, Index of /BeamTestPipeline/doc
Notes:
- Do not set the environmental variable for PIPELINE_HOME; that variable is used only within the installation instructions.
- However, do set the following variable:
setenv beamtestPlRoot /afs/slac.stanford.edu/g/glast/ground/PipelineConfig
/BeamTest-tasks/beamtestPipeline/versionNumber
(e.g., v1r030603p4)(The line shown above is wrapped.)
Also See:
| Owned by: | Tom Glanzman and Warren Focke |
| Last updated by: Chuck Patterson 08/28/2006-> |