Author: Matt Langston
Introduction
We currently use Oracle 9i for the production server, and Oracle 10g for the development and test servers. There are different procedures for recovering data from an Oracle disaster (for example, accientally dropping tables) depending on whether the server is Oracle 9i or 10g.
Ian MacGregor and I recently sat down together to figure out what GLAST should do in the event of Oracle data loss, and outline what is involved in recovering from such an event.
It is most difficult to recover from an Oracle 9i disaster. It is much easier to recover from an Oracle 10g disaster by making use of the new "Recycle Bin" feature.
Oracle 9i Recovery Procedure
SCS only backs up the production server, which is currently Oracle 9i. SCS does daily backups. However, it is still possible to recover data up to the point of a "drop table" event by making use of the daily backup from the previous day, plus the Oracle journaling features. What happens is that SCS restores the datatbase from the most recent backup, then uses Oracle journaling (similiar to a journaling file system) to recover data up to, but not including, the "drop table". Ian estimated it would take 2-3 hours to do such a recovery.
This procedure must be done by SCS - we cannot do it ourselvs.
Oracle 10g Recovery Procedure
The Oracle 10g Recycle Bin allows us to recover the data instantly, but we have to write a script to do the recovery. Recovering a dropped table from the recycle bin restores the table's column names, column data types, and the data itself, but nothing else. Specifically, it doesn't recover any constraints (primary key constraints, unique constraints, foreign key constraints, sequences, etc.). These all have to be restored manually after the data is recovered usng ALTER TABLE statements.
Note that it is always an option to have SCS do the "Oracle 9i style" recovery for us, but it means a 2-3 hours outage (or perhaps longer during off hours). The "Recycle Bin" method is an instant reovery procedure, but requires that we write a script to do the reovery using the procedure outlined below. Since we advertise 1 hour turn-around of our data processing, it seemed important to me that we consider the "Recycle Bin" method.
To recover a droped table, you first have to find its "object name" in the recycle bin. The following ColdFusion query will get everything you need to recover the GINO main tables.
| ColdFusion Not Required You don't need ColdFusion to do this query. It was just easiest for me to show it using a ColdFusion query since I wanted to easily show the GINO master table list, and I don't know PL/SQL well enough to show the same thing in a PL/SQL script. What is important is knowing the exact list of tables to recover, which is what the following example illustrates. |
<cfset gino_tables = ArrayNew(1) /> <cfset ArrayAppend(gino_tables, "TASK") /> <cfset ArrayAppend(gino_tables, "TASKTYPE") /> <cfset ArrayAppend(gino_tables, "TASKPROCESS") /> <cfset ArrayAppend(gino_tables, "BATCHGROUP") /> <cfset ArrayAppend(gino_tables, "BATCHQUEUE") /> <cfset ArrayAppend(gino_tables, "DATASET") /> <cfset ArrayAppend(gino_tables, "DSTYPE") /> <cfset ArrayAppend(gino_tables, "DSFILETYPE") /> <cfset ArrayAppend(gino_tables, "TP_DS") /> <cfset ArrayAppend(gino_tables, "TPINSTNACE") /> <cfset ArrayAppend(gino_tables, "PROCESSINGSTATUS") /> <cfset ArrayAppend(gino_tables, "DSINSTNACE") /> <cfset ArrayAppend(gino_tables, "TPI_DSI") /> <cfset ArrayAppend(gino_tables, "RUN") /> <cfset ArrayAppend(gino_tables, "RUNSTATUS") /> <cfset ArrayAppend(gino_tables, "USER") /> <cfset ArrayAppend(gino_tables, "ROLE") /> <cfset ArrayAppend(gino_tables, "USER_ROLE") /> <cfset ArrayAppend(gino_tables, "RECORDINFO") /> <cfset ArrayAppend(gino_tables, "RI_TASK") /> <cfset ArrayAppend(gino_tables, "RI_TASKPROCESS") /> <cfset ArrayAppend(gino_tables, "RI_DATASET") /> <cfset ArrayAppend(gino_tables, "RI_RUN") /> <cfquery name="qry" datasource="pipeline-dev"> select object_name, original_name, droptime, dropscn from recyclebin where original_name in (<cfqueryparam cfsqltype="cf_sql_varchar" list="yes" value="#ArrayToList(gino_tables)#" />) order by original_name asc, droptime desc </cfquery>
This query will return results similiar to the following:
| Object Name | Original Name | Drop Time | Drop SCN |
|---|---|---|---|
| BIN$8V58EOxtAjzgNAADuj+ROw==$0 | BATCHGROUP | 2005-03-02:16:12:28 | 1550952889 |
| BIN$8V52U8E8AjXgNAADuj+ROw==$0 | BATCHGROUP | 2005-03-02:16:10:52 | 1550951119 |
| BIN$8V58EOxmAjzgNAADuj+ROw==$0 | BATCHQUEUE | 2005-03-02:16:12:28 | 1550952876 |
| BIN$8V52U8E1AjXgNAADuj+ROw==$0 | BATCHQUEUE | 2005-03-02:16:10:52 | 1550951103 |
| BIN$8V58EOwRAjzgNAADuj+ROw==$0 | DATASET | 2005-03-02:16:12:27 | 1550952714 |
| BIN$8V52U8DgAjXgNAADuj+ROw==$0 | DATASET | 2005-03-02:16:10:51 | 1550950933 |
| BIN$8V58EOxDAjzgNAADuj+ROw==$0 | DSFILETYPE | 2005-03-02:16:12:27 | 1550952808 |
| BIN$8V52U8ESAjXgNAADuj+ROw==$0 | DSFILETYPE | 2005-03-02:16:10:52 | 1550951028 |
| BIN$8V58EOxKAjzgNAADuj+ROw==$0 | DSTYPE | 2005-03-02:16:12:27 | 1550952821 |
| BIN$8V52U8EZAjXgNAADuj+ROw==$0 | DSTYPE | 2005-03-02:16:10:52 | 1550951042 |
| BIN$8V58EOxRAjzgNAADuj+ROw==$0 | PROCESSINGSTATUS | 2005-03-02:16:12:28 | 1550952835 |
| BIN$8V52U8EgAjXgNAADuj+ROw==$0 | PROCESSINGSTATUS | 2005-03-02:16:10:52 | 1550951057 |
| BIN$8V58EOv3AjzgNAADuj+ROw==$0 | RECORDINFO | 2005-03-02:16:12:26 | 1550952663 |
| BIN$8V52U8DGAjXgNAADuj+ROw==$0 | RECORDINFO | 2005-03-02:16:10:50 | 1550950877 |
| BIN$8V58EOvNAjzgNAADuj+ROw==$0 | RI_DATASET | 2005-03-02:16:12:26 | 1550952559 |
| BIN$8V52U8CeAjXgNAADuj+ROw==$0 | RI_DATASET | 2005-03-02:16:10:50 | 1550950775 |
| BIN$8V58EOviAjzgNAADuj+ROw==$0 | RI_RUN | 2005-03-02:16:12:26 | 1550952611 |
| BIN$8V52U8CzAjXgNAADuj+ROw==$0 | RI_RUN | 2005-03-02:16:10:50 | 1550950829 |
| BIN$8V58EOvUAjzgNAADuj+ROw==$0 | RI_TASK | 2005-03-02:16:12:26 | 1550952577 |
| BIN$8V52U8ClAjXgNAADuj+ROw==$0 | RI_TASK | 2005-03-02:16:10:50 | 1550950792 |
| BIN$8V58EOvbAjzgNAADuj+ROw==$0 | RI_TASKPROCESS | 2005-03-02:16:12:26 | 1550952594 |
| BIN$8V52U8CsAjXgNAADuj+ROw==$0 | RI_TASKPROCESS | 2005-03-02:16:10:50 | 1550950810 |
| BIN$8V58EOxYAjzgNAADuj+ROw==$0 | ROLE | 2005-03-02:16:12:28 | 1550952848 |
| BIN$8V52U8EnAjXgNAADuj+ROw==$0 | ROLE | 2005-03-02:16:10:52 | 1550951073 |
| BIN$8V58EOwjAjzgNAADuj+ROw==$0 | RUN | 2005-03-02:16:12:27 | 1550952752 |
| BIN$8V52U8DyAjXgNAADuj+ROw==$0 | RUN | 2005-03-02:16:10:51 | 1550950972 |
| BIN$8V58EOx0AjzgNAADuj+ROw==$0 | RUNSTATUS | 2005-03-02:16:12:28 | 1550952903 |
| BIN$8V52U8FDAjXgNAADuj+ROw==$0 | RUNSTATUS | 2005-03-02:16:10:52 | 1550951135 |
| BIN$8V58EOw8AjzgNAADuj+ROw==$0 | TASK | 2005-03-02:16:12:27 | 1550952795 |
| BIN$8V58EOwzAjzgNAADuj+ROw==$0 | TASKPROCESS | 2005-03-02:16:12:27 | 1550952776 |
| BIN$8V52U8ECAjXgNAADuj+ROw==$0 | TASKPROCESS | 2005-03-02:16:10:51 | 1550950994 |
| BIN$8V58EOxfAjzgNAADuj+ROw==$0 | TASKTYPE | 2005-03-02:16:12:28 | 1550952862 |
| BIN$8V52U8EuAjXgNAADuj+ROw==$0 | TASKTYPE | 2005-03-02:16:10:52 | 1550951087 |
| BIN$8V58EOvGAjzgNAADuj+ROw==$0 | TPI_DSI | 2005-03-02:16:12:25 | 1550952541 |
| BIN$8V52U8CXAjXgNAADuj+ROw==$0 | TPI_DSI | 2005-03-02:16:10:49 | 1550950759 |
| BIN$8V58EOvpAjzgNAADuj+ROw==$0 | TP_DS | 2005-03-02:16:12:26 | 1550952630 |
| BIN$8V52U8C6AjXgNAADuj+ROw==$0 | TP_DS | 2005-03-02:16:10:50 | 1550950847 |
| BIN$8V58EOvwAjzgNAADuj+ROw==$0 | USER_ROLE | 2005-03-02:16:12:26 | 1550952645 |
It is important to only select the tables in the "where clause", since many other things are dropped when table is dropped that aren't easily restored (like all of the contraints listed above).
Notice that there are duplicate tables for most (but not all) of the primary GINO tables. This is becuase, for this particular example, the pdbschema.sql script was run twice, which did two "drop table" commands for each table. We want the earlier timestamp, which will be the tables that include the data we want to recover.
To recover the TASK table, execute this command:
flashback table "BIN$8V58EOw8AjzgNAADuj+ROw==$0" to before drop rename to task_scn_1550952795
| PL/SQL or SQL The flashback command is an Oracle PL/SQL command, and as such cannot be executed using tools like DbVisualizer. You must run something like SQL*Plus to execute these commands. |
The quotes around the "object_name" are important (otherwise you will get an error). The number in the name of the restored table (task_scn_1550952795 in the example above), comes from the "Drop SCN" column. This command will restore the TASK table to the uniqely named table named TASK_SCN_1550952795. Inspect this table to make sure it contains the data you think should be there. A simple "select * from task_scn_1550952795" should suffice. This will tell you if you reovered the correct version of the table, as the table could be listed multiple times depending on when the last time a purge was done.
Provided this is the table you want, then rename it to its proper name like so:
rename task_scn_1550952795 to task
Finally, apply whatver contraints are listed in pdbschema.sql. For this example, they would be something similiar to this:
alter table Task ( constraint PK_Task primary key (Task_PK), constraint FK_TaskType_Task foreign key (TaskType_FK) references TaskType (TaskType_PK), constraint NEW_TaskName unique (TaskName) );
As I followed the above procedure for the GLAST_DP dev database, executing the commnads manually from the PL/SQL prompt, I recovered the TASK table as show in the following figure:
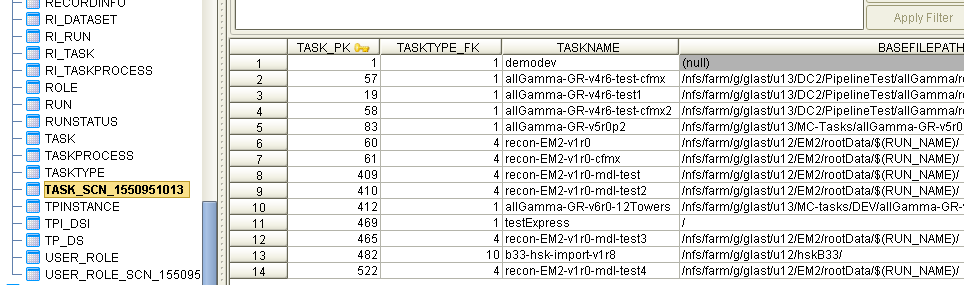
This should all be easy to automate in a new sql script, perhaps naming it pdb_data_recovery.sql