| Family | Variations |
|---|---|
| Differential coding | DPCM (Differential Pulse Code Modulation)
PDPCM (Predictive Differential Pulse Code Modulation) |
| Entropy coding | Huffman coding with fixed table
Huffman coding with variable table |
| Transformation coding | Wevelet coding
DCT(Discrete Cosine Tansformation) coding |
| Dynamic coding | None |
| Residual parametric coding | None |
| Run-Length coding | Mixed coding with Run-Length and 8 bits coding |
| Dictionary method | ALDC(Adaptive Lossless Data Compression)
DCLZ(Data Compression Lempel-Ziv) |
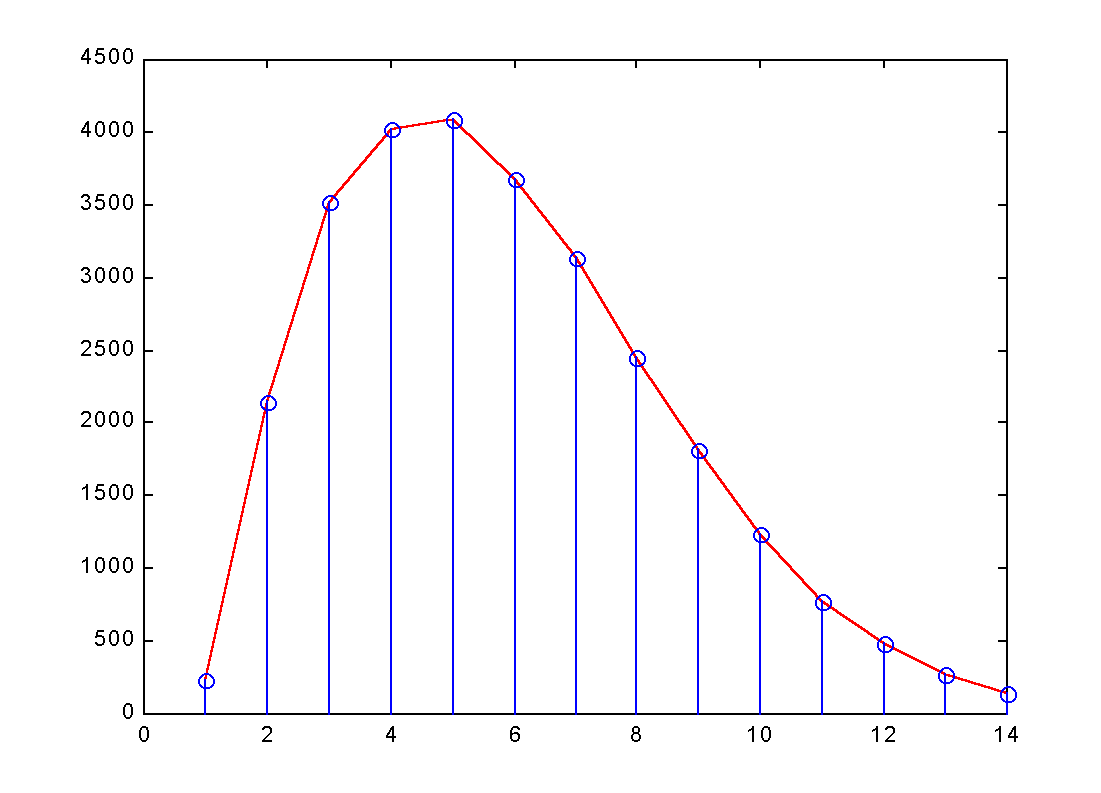
| Samplings | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
|
|
|
|
|
|||||||||||
|
|
|
|
|
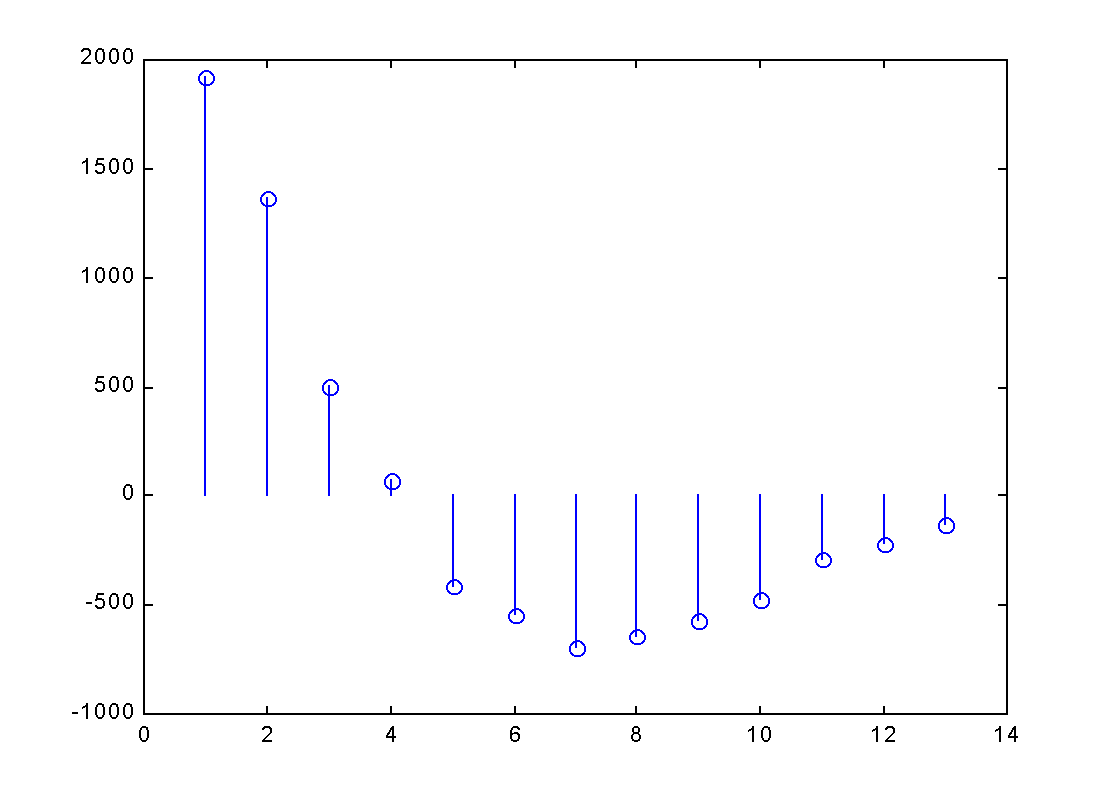
| Samplings | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
|
|
|
|
|
||||||||||||
|
|
|
|
|
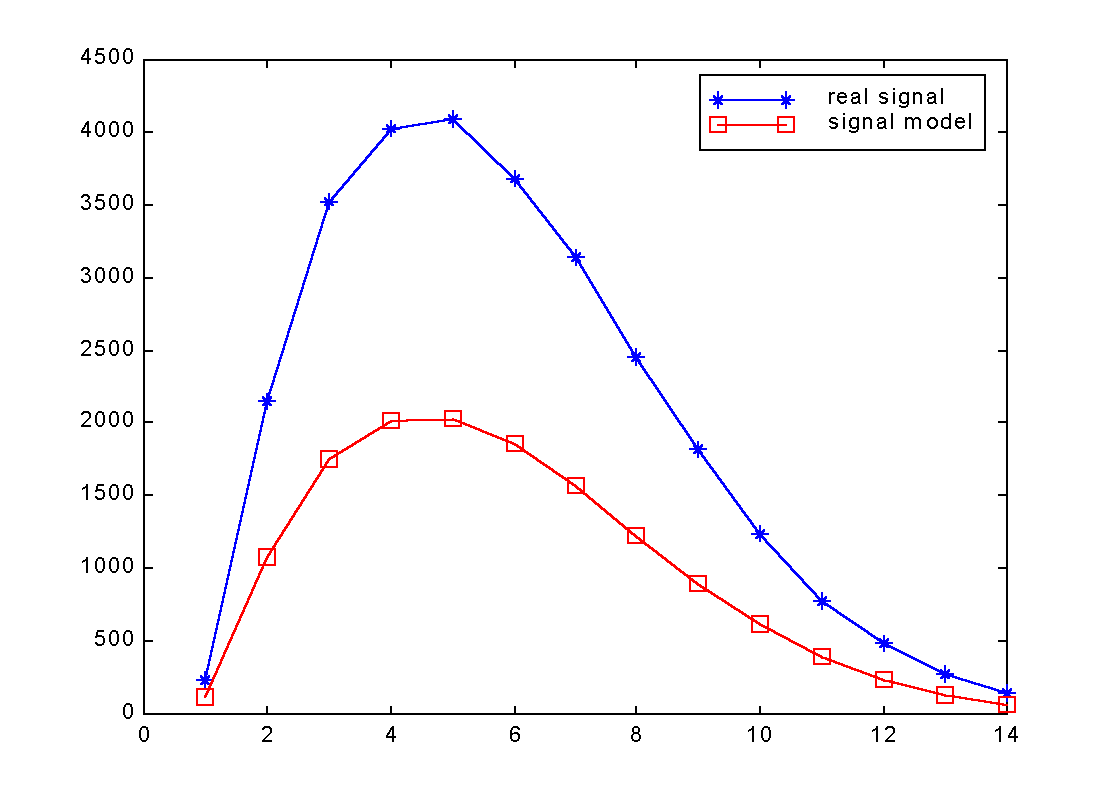
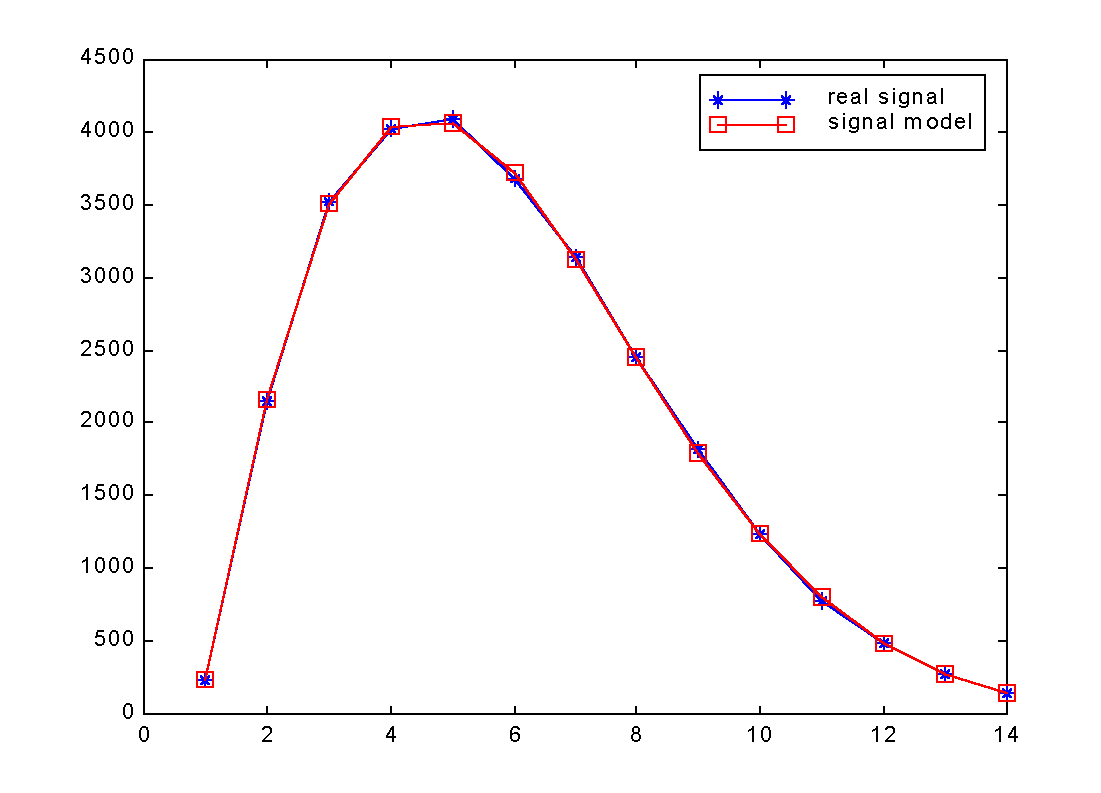
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
|
|
|
||
|
|
|||
|
|
|||
|
|
|||
|
|
|||
|
|
|||
|
|
|||
|
|
|||
|
|
|||
|
|
|||
|
|
|||
|
|
|||
|
|
|||
|
|
|||
|
|
|||
|
|
|||
|
|
|||
|
|
| SR type | event size | Huffman coding | compact |
|---|---|---|---|
| SR1(time+space) | |
|
|
| SR2-1(time, Et>2.5 GeV) | |
|
|
| SR2-2(time, Et>1.0 GeV) | |
|
|
| SR2-3(time, Et>0.5 GeV) | |
| |
| SR2-4(time, Et>0.3 GeV) | |
|
|
| SR type | event size | compress | gzip |
|---|---|---|---|
| SR1(time+space) | |
|
|
| SR2-1(time, Et>2.5 GeV) | |
|
|
| SR2-2(time, Et>1.0 GeV) | |
|
|
| SR2-3(time, Et>0.5 GeV) | |
| |
| SR2-4(time, Et>0.3 GeV) | |
|
|

| SR type | event size | dynamic coding | compression factor |
|---|---|---|---|
| SR1(time+space) | |
|
|
| SR2-1(time, Et>2.5 GeV) | |
|
|
| SR2-2(time, Et>1.0 GeV) | |
|
|
| SR2-3(time, Et>0.5 GeV) | |
| |
| SR2-4(time, Et>0.3 GeV) | |
|
|